
Dari Robot Bodoh ke Robot Pintar
Pernahkah kalian melihat robot pabrik yang melakukan gerakan yang sama berulang-ulang sepanjang hari? Itulah robot “bodoh” – mereka hanya bisa melakukan apa yang sudah diprogram sebelumnya. Kalau ada perubahan kecil saja, misalnya posisi benda bergeser sedikit, robot langsung bingung!
Tapi bayangkan kalau ada robot yang bisa belajar sendiri seperti manusia. Robot yang jatuh, lalu bangkit dan tahu cara berjalan lebih baik. Robot yang gagal mengambil benda, lalu mencoba lagi dengan cara berbeda sampai berhasil. Robot yang bisa beradaptasi dengan lingkungan baru tanpa perlu diprogram ulang.
Inilah era Physical AI – teknologi terbaru 2025 yang membuat robot bisa belajar dari pengalaman, mirip seperti kita belajar naik sepeda atau main video game!
Keren kan? Yuk kita bahas tuntas apa itu Physical AI dan bagaimana kita bisa mulai bereksperimen dengannya!
Apa Itu Physical AI?
Definisi Sederhana
Physical AI adalah kecerdasan buatan yang dirancang khusus untuk memahami dan berinteraksi dengan dunia fisik. Berbeda dengan AI biasa yang hanya bekerja dengan teks atau gambar (seperti ChatGPT), Physical AI membuat robot bisa:
- Melihat lingkungan sekitar dengan akurat
- Memahami hukum fisika (gravitasi, gesekan, momentum)
- Merencanakan gerakan yang efisien
- Belajar dari kesalahan dan pengalaman
- Beradaptasi dengan situasi baru
Analogi Mudah: Video Game vs Dunia Nyata
Ingat bagaimana AI bisa main catur atau game? Itu mudah karena aturannya jelas dan lingkungannya tidak berubah. Tapi dunia nyata jauh lebih rumit:
- Lantai bisa licin atau kasar
- Benda bisa bergeser atau jatuh
- Cahaya bisa terang atau gelap
- Orang bisa tiba-tiba lewat
Physical AI dirancang untuk menghadapi kompleksitas dunia nyata ini!
Kenapa Physical AI Jadi Hot di 2025?
1. Terobosan Teknologi Terbaru
Physical AI memungkinkan robot belajar dalam simulasi virtual sebelum diterapkan ke dunia nyata, menghemat waktu dan biaya pelatihan yang sangat besar.
Dahulu:
- Training robot = jutaan percobaan di dunia nyata
- Waktu: berbulan-bulan bahkan bertahun-tahun
- Risiko: robot rusak, berbahaya, mahal
Sekarang dengan Physical AI:
- Training di simulasi virtual = unlimited percobaan
- Waktu: hitungan jam atau hari
- Risiko: NOLL! Kalau robot jatuh di simulasi, tinggal reset
- Transfer ke dunia nyata: otomatis!
2. Hardware Semakin Terjangkau
GPU dan sensor canggih kini lebih murah dan powerful, membuat teknologi ini tidak lagi eksklusif untuk perusahaan besar.
3. Software Open Source
Platform seperti NVIDIA Isaac Sim, Gazebo, dan PyBullet kini gratis dan mudah diakses siapa saja – termasuk kita!
4. Aplikasi Real-World yang Massive
Physical AI akan mengubah berbagai industri dari manufaktur, logistik, hingga healthcare, menciptakan peluang karir baru yang menjanjikan.
Bagaimana Physical AI Bekerja?
3 Pilar Utama Physical AI
1. Perception (Persepsi)
Robot harus bisa “melihat” dan “merasakan” lingkungannya:
- Camera Vision: Melihat objek, jarak, dan ruang 3D
- Sensors: LiDAR, IMU, force sensor, tactile sensor
- Data Processing: Mengubah sensor data jadi informasi berguna
2. Planning (Perencanaan)
Robot harus bisa membuat keputusan:
- Path Planning: Rute terbaik dari A ke B
- Motion Planning: Gerakan yang smooth dan efisien
- Task Planning: Urutan tindakan untuk mencapai tujuan
3. Learning (Pembelajaran)
Robot belajar dari pengalaman:
- Reinforcement Learning: Belajar dari trial-and-error
- Imitation Learning: Belajar dari meniru manusia
- Transfer Learning: Transfer skill dari simulasi ke dunia nyata
Workflow Physical AI (Simplified)
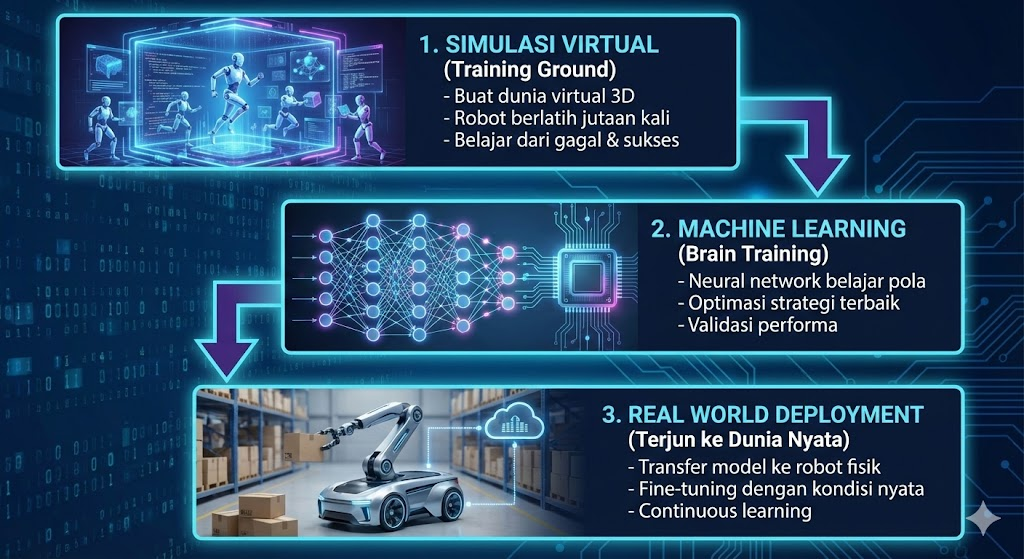
Platform dan Tools untuk Belajar Physical AI
1. NVIDIA Isaac Sim ⭐ (Recommended untuk Pemula)
Apa itu? Isaac Sim adalah platform simulasi robotik berbasis Omniverse yang menggunakan rendering photorealistic dan physics engine akurat.
Keunggulan:
- ✅ Gratis untuk personal use
- ✅ Grafis super realistis (seperti game AAA)
- ✅ Physics engine akurat (gravitasi, gesekan, collision)
- ✅ Library robot siap pakai
- ✅ Integrasi dengan ROS (Robot Operating System)
- ✅ Support GPU acceleration untuk training cepat
System Requirements:
- OS: Windows 10/11 atau Linux
- GPU: NVIDIA RTX series (minimal GTX 1060)
- RAM: 16GB (32GB recommended)
- Storage: 50GB free space
Download: developer.nvidia.com/isaac-sim
2. Gazebo (Open Source Alternative)
Keunggulan:
- ✅ Completely free & open source
- ✅ Large community support
- ✅ Works on CPU (no GPU needed)
- ✅ ROS integration
Cocok untuk: Yang komputernya tidak punya GPU kuat
3. PyBullet (Lightweight & Python-Friendly)
Keunggulan:
- ✅ Super lightweight
- ✅ Easy Python API
- ✅ Fast iteration
- ✅ Good for learning basics
Cocok untuk: Coding-first learners, rapid prototyping
4. Webots (Educational Focus)
Keunggulan:
- ✅ User-friendly interface
- ✅ Built-in robot models
- ✅ Great documentation
- ✅ Cross-platform
Cocok untuk: Students, beginners
Tutorial Praktis: Membuat Robot Pertama yang Belajar Sendiri
Mari kita mulai dengan proyek sederhana: Robot yang belajar menjaga keseimbangan (seperti Segway atau robot self-balancing).
Prerequisites:
- Komputer dengan NVIDIA GPU (atau gunakan PyBullet untuk CPU)
- Python 3.8+
- Basic understanding Python
Step 1: Install Tools
Untuk NVIDIA Isaac Sim:
# Download dari website NVIDIA
# Install sesuai instruksi installer
Atau PyBullet (Lebih Mudah):
pip install pybullet
pip install gym
pip install stable-baselines3
pip install numpy matplotlib
Step 2: Create Simple Robot Simulation
Mari kita buat robot cart dengan pole yang harus dijaga tetap berdiri (CartPole problem – klasik untuk belajar RL):
import gymnasium as gym
import numpy as np
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
import matplotlib.pyplot as plt
# === BAGIAN 1: SETUP ENVIRONMENT ===
print(" Membuat Simulasi Robot...")
# Buat environment CartPole
# CartPole = robot cart dengan pole yang harus dijaga tetap tegak
env = gym.make('CartPole-v1', render_mode='rgb_array')
print(" Environment siap!")
print(f" - Action space: {env.action_space}") # 0=kiri, 1=kanan
print(f" - Observation space: {env.observation_space}") # posisi, velocity, angle, angular velocity
# === BAGIAN 2: LIHAT ROBOT SEBELUM TRAINING ===
print("\n Mari lihat robot SEBELUM belajar (masih bodoh)...")
def test_robot(model=None, episodes=3, max_steps=200):
"""Test robot dan return total reward"""
total_rewards = []
for episode in range(episodes):
obs, info = env.reset()
episode_reward = 0
for step in range(max_steps):
if model is None:
# Random action (robot bodoh)
action = env.action_space.sample()
else:
# AI-powered action (robot pintar)
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env.step(action)
episode_reward += reward
if terminated or truncated:
break
total_rewards.append(episode_reward)
print(f" Episode {episode+1}: Score = {episode_reward:.0f}")
avg_reward = np.mean(total_rewards)
print(f" Average Score: {avg_reward:.1f}")
return avg_reward
# Test robot bodoh (random actions)
before_score = test_robot(model=None)
# === BAGIAN 3: TRAINING - ROBOT BELAJAR! ===
print("\nMULAI TRAINING - Robot sedang belajar...")
print(" (Ini akan memakan waktu beberapa menit)")
# Buat vectorized environment untuk training lebih cepat
vec_env = make_vec_env('CartPole-v1', n_envs=4)
# Buat AI model menggunakan PPO (Proximal Policy Optimization)
# PPO adalah algoritma Reinforcement Learning yang populer
model = PPO(
"MlpPolicy", # Multi-Layer Perceptron (Neural Network)
vec_env,
verbose=0,
learning_rate=0.001,
n_steps=2048,
batch_size=64,
n_epochs=10,
)
# Training loop dengan progress tracking
training_scores = []
timesteps_per_check = 10000
total_timesteps = 100000
print(f" Target: {total_timesteps} timesteps")
for i in range(total_timesteps // timesteps_per_check):
# Train
model.learn(total_timesteps=timesteps_per_check, reset_num_timesteps=False)
# Test current performance
test_env = gym.make('CartPole-v1')
obs, _ = test_env.reset()
episode_reward = 0
for _ in range(500):
action, _ = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, _ = test_env.step(action)
episode_reward += reward
if terminated or truncated:
break
test_env.close()
training_scores.append(episode_reward)
progress = (i + 1) * timesteps_per_check
print(f" Progress: {progress}/{total_timesteps} - Score: {episode_reward:.0f}")
print("\n TRAINING SELESAI!")
# === BAGIAN 4: TEST ROBOT SETELAH BELAJAR ===
print("\n Mari lihat robot SETELAH belajar (sudah pintar)...")
# Buat environment baru untuk testing
test_env = gym.make('CartPole-v1', render_mode='rgb_array')
env = test_env
after_score = test_robot(model=model)
# === BAGIAN 5: VISUALISASI HASIL ===
print("\n Membuat grafik perbandingan...")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
# Grafik 1: Before vs After
ax1.bar(['Before Training\n(Random)', 'After Training\n(AI-Powered)'],
[before_score, after_score],
color=['#ff6b6b', '#51cf66'])
ax1.set_ylabel('Average Score')
ax1.set_title(' Robot Performance: Before vs After Learning', fontsize=14, fontweight='bold')
ax1.set_ylim(0, max(before_score, after_score) * 1.2)
# Tambahkan nilai di atas bar
for i, (score, label) in enumerate([(before_score, 'Before'), (after_score, 'After')]):
ax1.text(i, score + 5, f'{score:.1f}', ha='center', fontweight='bold')
# Grafik 2: Learning Progress
ax2.plot(range(len(training_scores)), training_scores, linewidth=2, color='#4dabf7')
ax2.fill_between(range(len(training_scores)), training_scores, alpha=0.3, color='#4dabf7')
ax2.set_xlabel('Training Checkpoints')
ax2.set_ylabel('Score')
ax2.set_title('📈 Learning Progress Over Time', fontsize=14, fontweight='bold')
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('robot_learning_results.png', dpi=150, bbox_inches='tight')
print(" Grafik tersimpan sebagai 'robot_learning_results.png'")
plt.show()
# === BAGIAN 6: KESIMPULAN ===
print("\n" + "="*60)
print("HASIL PEMBELAJARAN ROBOT:")
print("="*60)
print(f" Score SEBELUM belajar: {before_score:.1f}")
print(f" Score SETELAH belajar: {after_score:.1f}")
improvement = ((after_score - before_score) / before_score) * 100
print(f" Peningkatan: {improvement:.1f}%")
print("="*60)
print("\n Apa yang Terjadi?")
print(" Robot belajar dari trial-and-error:")
print(" 1. Mencoba berbagai gerakan")
print(" 2. Mendapat reward saat pole tetap tegak")
print(" 3. Belajar strategi terbaik dari pengalaman")
print(" 4. Semakin lama semakin pintar!")
print("\n Ini adalah Reinforcement Learning - konsep dasar Physical AI!")
# Cleanup
env.close()
Penjelasan Kode:
1. Environment Setup
env = gym.make('CartPole-v1')
Membuat simulasi robot cart dengan pole. Robot harus menjaga pole tetap tegak dengan menggerakkan cart kiri-kanan.
2. State (Observasi) Robot “melihat” 4 hal:
- Posisi cart
- Kecepatan cart
- Sudut pole
- Kecepatan angular pole
3. Actions (Aksi) Robot punya 2 pilihan setiap waktu:
- 0 = Dorong cart ke KIRI
- 1 = Dorong cart ke KANAN
4. Reward System
- +1 reward setiap timestep pole tetap tegak
- Episode selesai kalau pole jatuh atau cart keluar batas
5. Learning Algorithm (PPO)
model = PPO("MlpPolicy", vec_env, ...)
PPO (Proximal Policy Optimization) adalah algoritma yang:
- Mencoba berbagai strategi
- Mengukur mana yang paling berhasil
- Gradually improve policy (strategi)
- Balance antara exploration (coba hal baru) dan exploitation (pakai yang sudah terbukti bagus)
Step 3: Jalankan dan Amati
python robot_learning.py
Apa yang Akan Terjadi:
- Menit 1-2: Robot sangat bodoh, pole langsung jatuh
- Menit 3-5: Robot mulai belajar, pole bertahan lebih lama
- Menit 5+: Robot makin pintar, bisa jaga keseimbangan lama!
Hasil yang Diharapkan:
- Before Training: Score ~20-30
- After Training: Score ~200-500
Upgrade: Proyek Physical AI yang Lebih Advanced
Setelah berhasil dengan CartPole, kalian bisa lanjut ke proyek lebih kompleks:
1. Humanoid Walking Robot
import gymnasium as gym
from stable_baselines3 import SAC
# Environment humanoid yang belajar berjalan
env = gym.make('Humanoid-v4')
# SAC = Soft Actor-Critic (bagus untuk continuous control)
model = SAC("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=1_000_000)
Challenge:
- 17 joints yang harus dikontrol
- Balance sambil bergerak maju
- Koordinasi seluruh tubuh
2. Robot Arm Manipulation
import gymnasium as gym
import pybullet_envs
# Robot arm yang belajar pick and place
env = gym.make('ReacherBulletEnv-v0')
# Training untuk reach target position
model = TD3("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=500_000)
Challenge:
- Inverse kinematics
- Collision avoidance
- Precise positioning
3. Quadruped Robot (Robot Berkaki Empat)
# Simulasi robot anjing/kucing
env = gym.make('Ant-v4') # Atau gunakan real quadruped model
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=2_000_000)
Challenge:
- Gait coordination (koordinasi langkah)
- Terrain adaptation
- Energy efficiency
Roadmap: Dari Simulasi ke Robot Fisik
Phase 1: Simulasi (Minggu 1-4)
✅ Belajar konsep dasar RL
✅ Eksperimen dengan berbagai environment
✅ Training dan optimization
✅ Validasi performa di simulasi
Phase 2: Sim-to-Real Transfer (Minggu 5-8)
📦 Beli/rakit robot fisik
🔧 Install sensor dan aktuator
💾 Deploy trained model ke robot
🎯 Fine-tuning dengan real-world data
Phase 3: Real-World Testing (Minggu 9-12)
🧪 Test di berbagai kondisi
📊 Collect performance metrics
🔄 Iterative improvement
🚀 Production ready!
Tips Sim-to-Real:
1. Domain Randomization
# Randomize parameters di simulasi untuk generalisasi lebih baik
config = {
'friction': random.uniform(0.5, 1.5),
'mass': random.uniform(0.8, 1.2),
'noise': random.uniform(0, 0.1)
}
2. System Identification
- Ukur parameter fisik robot yang akurat
- Kalibrasi sensor
- Tuning simulasi supaya match dengan real robot
3. Progressive Deployment
- Start dengan simple task
- Gradually increase complexity
- Always have safety measures!
Physical AI di Industri: Real-World Applications
1. Warehouse Robotics
Robot yang belajar mengoptimalkan picking dan packing di gudang, mengurangi waktu proses hingga 50%.
Contoh: Amazon Robotics, Ocado
2. Manufacturing & Assembly
Robot yang bisa beradaptasi dengan variasi produk tanpa reprogramming manual.
Contoh: Tesla Optimus, Boston Dynamics Spot
3. Healthcare & Elderly Care
Robot assistive yang belajar membantu pasien dengan kebutuhan berbeda-beda.
Contoh: Moxi (hospital assistant), Paro (therapy robot)
4. Agriculture
Robot yang belajar memetik buah, menyiangi gulma, dan monitoring tanaman.
Contoh: FarmWise, Iron Ox
5. Last-Mile Delivery
Robot delivery yang belajar navigasi di lingkungan urban yang kompleks.
Contoh: Starship Technologies, Nuro
Tantangan Physical AI
1. Sim-to-Real Gap
Simulasi tidak 100% sempurna. Robot yang perfect di simulasi bisa struggle di dunia nyata karena:
- Friction yang berbeda
- Sensor noise
- Actuator imperfections
- Environmental variations
Solusi: Domain randomization, system identification, real-world fine-tuning
2. Safety Concerns
Robot yang belajar bisa melakukan hal unexpected. Perlu:
- Safety constraints
- Emergency stop system
- Monitoring continuous
- Redundancy systems
3. Computational Requirements
Training butuh GPU powerful dan waktu. Bisa mahal untuk hobbyist.
Solusi:
- Pakai cloud computing (Google Colab, AWS)
- Start dengan model sederhana
- Leverage pre-trained models
4. Data Collection
Real-world data mahal dan time-consuming.
Solusi:
- Maksimalkan simulasi
- Transfer learning
- Data augmentation
Resources untuk Belajar Lebih Dalam
Courses Online:
- Coursera – Reinforcement Learning Specialization (University of Alberta)
- Udacity – Robotics Software Engineer Nanodegree
- DeepMind x UCL – Reinforcement Learning Lecture Series (YouTube – GRATIS!)
Books:
- “Reinforcement Learning: An Introduction” – Sutton & Barto (Bible-nya RL)
- “Deep Reinforcement Learning Hands-On” – Maxim Lapan
- “Probabilistic Robotics” – Thrun, Burgard, Fox
Communities:
- r/reinforcementlearning (Reddit)
- ROS Discourse (forum resmi ROS)
- Discord: AI & Robotics Indonesia
- GitHub: Trending in Robotics
YouTube Channels:
- Two Minute Papers – AI news dijelaskan simpel
- Lex Fridman – Interview dengan experts
- Arxiv Insights – Paper explanation
Tips untuk Pemula
1. Mulai dari yang Simpel
Jangan langsung bikin robot humanoid! Mulai dari:
- ✅ CartPole (balance)
- ✅ MountainCar (momentum)
- ✅ Pendulum (control)
- ✅ LunarLander (coordination)
2. Understand the Basics
Sebelum terjun ke code, pahami dulu:
- Markov Decision Process (MDP)
- Value function & Policy
- Exploration vs Exploitation
- Reward engineering
3. Experiment & Iterate
- Coba berbagai hyperparameters
- Test berbagai algoritma (PPO, SAC, TD3)
- Document apa yang work dan apa yang tidak
- Jangan takut gagal!
4. Join Community
- Share progress di social media
- Minta feedback dari orang lain
- Contribute ke open source projects
- Attend hackathons dan competitions
5. Think About Applications
- Apa masalah real-world yang bisa dipecahkan?
- Apakah solutionnya feasible?
- Bagaimana monetization-nya?
Future of Physical AI: Apa yang Akan Datang?
2025-2027: Foundation Era
- Standardisasi platform dan tools
- More accessible hardware
- Improved sim-to-real techniques
- Wider industry adoption
2027-2030: Integration Era
- Physical AI + Large Language Models
- Multi-modal learning (vision + language + touch)
- Swarm robotics dengan AI coordination
- Home robots yang truly useful
2030+: Ubiquitous Era
- Robot assistants di setiap rumah
- Autonomous vehicles mainstream
- AI-powered humanoids di service industry
- Human-robot collaboration seamless
Kesimpulan
Physical AI adalah revolusi besar di dunia robotika. Yang dulunya butuh tim engineer berpuluh-puluh orang dan waktu bertahun-tahun untuk program satu robot, sekarang bisa dilakukan dalam hitungan minggu dengan machine learning!
Key Takeaways:
🎯 Physical AI = AI untuk Dunia Fisik
- Robot belajar dari pengalaman
- Training di simulasi, deploy ke real world
- Adaptif dan scalable
🚀 Teknologi Sudah Tersedia
- Tools gratis dan open source
- Community besar dan supportive
- Dokumentasi lengkap
💡 Siapa Saja Bisa Mulai
- Tidak perlu background PhD
- Basic programming sudah cukup
- Start small, scale gradually
🌟 Masa Depan Cerah
- Job opportunities melimpah
- Impact ke berbagai industri
- Innovation space yang luas
Jangan tunggu besok, mulai hari ini! Download PyBullet atau Isaac Sim, ikuti tutorial di artikel ini, dan create your first learning robot. Siapa tahu robot buatan kalian jadi next big thing di dunia robotika! 🚀
Call to Action
Sudah siap membuat robot pintar pertama kalian?
- ⬇️ Download tools (PyBullet untuk start cepat)
- 💻 Copy paste kode di artikel ini
- ▶️ Run dan lihat robot belajar
- 📸 Share hasilnya di kolom komentar!
- 🤝 Join komunitas dan tanya-tanya
Punya pertanyaan? Drop di kolom komentar!
Berhasil training robot? Share screenshot-nya!
Stuck di tengah jalan? Tim jagorobotik siap bantu!
Happy Learning & Keep Building! 🤖✨
Artikel ini dibuat untuk jagorobotik.com
Follow kami untuk update artikel robotik terbaru!
Bonus: Quick Reference Commands
# Install dependencies
pip install gymnasium pybullet stable-baselines3 numpy matplotlib
# Run basic training
python robot_learning.py
# Monitor training (optional)
tensorboard --logdir ./logs/
# Export trained model
model.save("my_robot_brain")
# Load and use model
model = PPO.load("my_robot_brain")
Selamat Bereksperimen! 🎉
